2026年初,全球每周已有超过2.3亿人在AI平台上咨询健康问题-4;全球AI医疗健康市场规模预计年内将达到560亿美元-4;在国内,截至2026年1月,AI医疗相关企业存量已达10.8万家,近十年相关专利申请量持续攀升-4——医用AI助手正从一个前沿技术概念,迅速转变为医疗体系中不可或缺的基础设施。面对这一技术热潮,许多学习者却陷入“会用但不懂原理”的尴尬:能调用大模型API完成医疗问答,却说不清检索增强生成与多智能体协作的区别;能用LangChain搭建简易助手,却在面试中被问到RAG底层原理时语塞。本文将从技术痛点到底层原理,从代码示例到面试考点,帮你建立医用AI助手的完整知识链路。全文结构如下:首先剖析传统实现方式的痛点,引出技术设计初衷;接着系统讲解LLM Agent与RAG两大核心概念及其关系;然后通过可运行的代码示例展示实现流程;最后提炼高频面试题与参考答案。文中技术栈以LLM(Large Language Model,大语言模型)、RAG(Retrieval-Augmented Generation,检索增强生成)和Agentic框架为主线。
一、痛点切入:为什么需要医用AI助手?
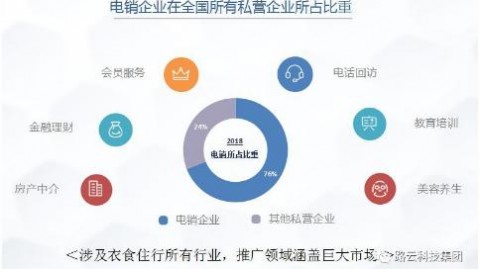
在没有大语言模型支撑的年代,医疗问答系统主要采用两种传统实现方式。
方式一:基于规则匹配的FAQ问答。 系统维护一个固定的“问题-答案”键值对数据库,通过关键词匹配或正则表达式来查找答案。例如,用户输入“头疼是什么原因”,系统提取关键词“头疼”,匹配到预定义问题“头疼的原因有哪些”,返回写死的回答。

方式二:基于意图识别的对话机器人。 系统先训练一个文本分类模型,将用户输入归类到预设的意图类别(如“症状咨询”“用药查询”“挂号引导”),再根据意图类别调用相应的回复模板或API。
传统方式的致命缺陷:
知识更新滞后。 规则和模板一旦构建,新增医学知识就需要人工逐一更新问答对或训练数据,无法实时获取最新医学指南或临床证据。
语义理解能力有限。 “头疼”和“头部隐隐作痛”无法匹配,“我这两天总是觉得头晕”也无法被精准理解。传统系统无法处理长文本、复杂上下文和隐含信息。
可扩展性差。 每新增一个疾病领域,几乎都需要重新整理问答库或重新训练意图分类模型,维护成本极高。
缺少推理链条。 面对“发烧三天+咳嗽+近期接触过流感患者,可能是什么病”这类多因素综合判断,传统系统只能给出碎片化答案,缺乏从症状到诊断的完整推理过程。
正是这些痛点,催生了基于LLM的医用AI助手。它不再依赖写死的规则库,而是通过大模型的语义理解能力,结合检索增强生成与智能体架构,实现灵活、精准、可解释的医疗问答与辅助诊断。
二、核心概念讲解:LLM Agent
LLM Agent,全称为Large Language Model Agent(大语言模型智能体),是指以大语言模型作为“大脑”核心,能够自主理解用户意图、规划任务步骤、调用外部工具,并最终执行任务的智能化系统。
用一句话拆解其内涵:LLM是思考的“大脑”,Agent是能行动的“大脑”。 传统的LLM只做一件事——根据输入生成输出(即“问答”),但Agent让它具备了三个额外能力:
规划能力:将复杂任务拆解为多个子步骤。例如,面对“帮我查一下糖尿病的饮食注意事项,并总结成3条”这个任务,Agent会规划:第一步糖尿病饮食相关信息 → 第二步提取关键注意事项 → 第三步归纳为3条。
工具调用能力:能够主动调用外部API、引擎、数据库等工具获取额外信息,弥补LLM自身知识的局限性。
记忆能力:维护短期记忆(当前对话上下文)和长期记忆(用户历史信息、偏好等),实现持续的个性化服务。
生活化类比: LLM Agent就像一个“能干的医疗助理”。普通LLM是“只会背书的理论派”——你问他糖尿病的定义,他能准确背诵;而Agent是“会做事的工作派”——你让它“帮我约个周三的专家号”,它能拆解步骤:先查专家排班表 → 确认空闲时段 → 调用挂号API完成预约。
在医用AI助手场景中,Agent的价值尤为突出。医疗问诊通常是长链路、多步骤的任务执行:病历生成、文献检索、路径验证,其本质上是持续的高强度推理负载-。一个典型的医疗Agent需要:①理解患者主诉 → ②检索相关医学知识库 → ③分析症状与疾病的关联 → ④生成诊断建议 → ⑤追问缺失信息。每步都可能调用不同的工具(药物数据库、检验指南、医学文献库等),这正是Agent擅长的工作方式。
三、关联概念讲解:RAG(检索增强生成)
RAG,全称Retrieval-Augmented Generation(检索增强生成),是一种将外部知识检索与大语言模型生成能力相结合的混合架构。简单来说,RAG让LLM不再仅仅依赖训练时“记住”的静态知识,而是能够在回答问题时,先从外部知识库中检索相关信息,再基于检索到的内容生成答案-。
RAG的核心工作流程:
用户提问 → 向量化Query → 知识库检索(相似度匹配)→ 召回相关文本片段 → 拼接Prompt → LLM生成答案在医用AI助手场景中,RAG解决了大模型在医疗领域的两个核心难题:
难题一:知识静态与过时风险。 LLM训练完成后,其参数中编码的知识就凝固了。但医学知识是动态更新的——每年有数万篇新的临床研究论文发表,新的诊疗指南不断发布。RAG让系统能够实时检索最新医学文献,让答案始终保持时效性-24。
难题二:专业领域知识不足。 通用LLM在医学细分领域的知识密度不够,容易出现“幻觉”(Hallucination)——编造不存在的药物名称或诊疗方案。RAG通过检索权威医学知识库(如药品说明书、诊疗指南、电子病历),用事实支撑生成,大幅降低了幻觉风险。
研究表明,基于RAG的动态提示策略在生物医学命名实体识别(Named Entity Recognition,简称NER)任务中,能够将GPT-4的F1分数相对提升12%-40。在医疗问答系统中,结合RAG的少样本思维链(Few-shot Chain of Thought,简称Few-shot CoT)方法,在临床准确性和可解释性方面分别获得了0.89和0.905的高分-45。
四、概念关系与区别总结
理解了LLM Agent和RAG各自的内涵后,最关键的问题是:它们是什么关系? 很多初学者容易混淆这两个概念,甚至在面试中答非所问。以下是清晰的关系总结:
| 维度 | LLM Agent | RAG |
|---|---|---|
| 定位 | 架构范式 / 设计思想 | 具体技术实现 |
| 核心目标 | 让LLM具备自主行动和任务规划能力 | 让LLM能够检索外部知识来增强回答 |
| 解决问题 | 多步骤任务执行、工具调用 | 知识时效性、幻觉问题、专业领域深度 |
| 依赖关系 | RAG是Agent常用的一种“知识获取”工具 | Agent是RAG能力发挥的系统载体 |
一句话概括二者关系:RAG解决“不知道的知识如何获取”,Agent解决“复杂的事情如何做完”;一个医用AI助手通常是“以Agent为骨架、以RAG为引擎”的整体架构。
实际应用中,二者常常协同工作。以MedRAG这个开源的医疗多模态助手为例,它既利用RAG检索知识图谱来增强诊断推理,又具备多模态输入处理能力(语音监测、电子健康记录等),本质上是一个整合了RAG能力的Agent系统-54。
五、代码示例:基于RAG的医用问答助手
下面是一个极简但完整的医用问答助手实现,使用LangChain框架和Chroma向量数据库。
导入依赖库(pip install langchain chromadb openai) import os from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.chat_models import ChatOpenAI from langchain.chains import RetrievalQA from langchain.document_loaders import TextLoader from langchain.text_splitter import CharacterTextSplitter Step 1: 准备医学知识文档(此处以模拟数据为例) medical_docs = [ "高血压诊断标准:收缩压≥140mmHg和/或舒张压≥90mmHg,非同日3次测量。", "糖尿病典型症状:多饮、多尿、多食、体重下降(三多一少),空腹血糖≥7.0mmol/L。", "普通感冒症状:流鼻涕、打喷嚏、喉咙痛,通常7天内自愈。", "布洛芬用法用量:成人每次200-400mg,每日3-4次,最大日剂量1200mg。" ] Step 2: 文档分块与向量化(将文本转换为数值向量,用于相似度检索) text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20) docs = [{"page_content": doc} for doc in medical_docs] split_docs = [] for doc in docs: chunks = text_splitter.split_text(doc["page_content"]) for chunk in chunks: split_docs.append({"page_content": chunk}) Step 3: 构建向量数据库(使用Chroma存储和检索) embeddings = OpenAIEmbeddings() 将文本转为向量 vectorstore = Chroma.from_documents( documents=[doc["page_content"] for doc in split_docs], embedding=embeddings ) Step 4: 配置检索器(retriever),指定返回top-k个最相关文档 retriever = vectorstore.as_retriever(search_kwargs={"k": 2}) Step 5: 构建RAG问答链 llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) temperature=0保证输出确定性 qa_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", retriever=retriever, return_source_documents=True 返回检索到的源文档,增强可解释性 ) Step 6: 执行问答 query = "我最近总是口渴、小便多、吃饭也多但体重还在下降,可能是什么问题?" result = qa_chain({"query": query}) print(f"问题:{query}") print(f"答案:{result['result']}") print(f"参考来源:{[doc.page_content for doc in result['source_documents']]}")
执行流程详解:
用户提问 → 输入自然语言问题
Query向量化 → Embedding模型将问题转换为向量表示
相似度检索 → 在向量数据库中查找与Query向量最相似的2个文档片段
上下文拼接 → 将检索到的文档片段与原始问题组合成Prompt:“根据以下资料回答问题:\n[检索到的内容]\n问题:[用户问题]”
LLM生成 → 大模型基于检索到的证据生成最终答案
返回答案+来源 → 同时输出答案和引用的知识片段
关键设计要点标注:
temperature=0:降低模型输出的随机性,确保医疗回答的稳定性和一致性k=2:平衡检索广度与上下文长度,避免过多无关信息干扰return_source_documents=True:可解释性设计,让用户知道答案的来源
六、底层原理与技术支撑
医用AI助手的底层依赖以下几个关键技术:
1. 向量数据库与近似最近邻检索(Approximate Nearest Neighbor, ANN)
RAG的核心效率瓶颈在于检索速度。医疗知识库动辄百万级文档,线性检索不可行。ANN算法(如HNSW、IVF)在牺牲极小精度的情况下,将检索时间从O(N)降到O(log N),实现毫秒级响应。
2. Embedding模型与语义理解
传统的关键词匹配无法处理同义词和语义相近的表达。Embedding模型(如BERT-based、OpenAI embedding)将文本映射到高维向量空间,使得“头疼”与“头部疼痛”的向量距离很近,实现真正的语义检索。
3. Prompt Engineering(提示工程)
在医疗场景中,Prompt设计直接影响回答质量。研究表明,结构化的静态提示相比基础提示,可将GPT-4的F1分数提升12%-40。医疗RAG的Prompt通常需要包含:角色设定(“你是一位专业的医疗助手”)、检索内容注入、输出格式约束(如“分条列出诊断依据”)、安全边界声明(“建议咨询执业医师”)。
4. 多智能体协作框架
复杂医疗任务通常需要多个专业智能体协同工作。例如,规划智能体负责拆解任务、编码智能体负责生成查询代码、执行智能体负责调用API,三者协作完成完整的数据分析流程-。MedCollab等研究提出了基于因果推理的多智能体诊断框架,通过结构化论辩机制减少诊断幻觉-。
5. 知识图谱增强RAG
传统RAG检索的是文本片段,缺乏实体之间的逻辑关联。图谱增强RAG在传统RAG基础上引入知识图谱(Knowledge Graph, KG),将图结构引入文本索引和检索,采用双层检索系统,能够捕捉疾病、症状、药物之间的因果依赖关系-20。这在医疗诊断中尤为重要——仅检索“发烧”和“咳嗽”两个片段,无法理解它们与“肺炎”之间的医学关联;而知识图谱能够输出“关系路径+证据链”,提升复杂推理场景的准确度与可解释性-20。
七、高频面试题与参考答案
Q1:请简要解释RAG(检索增强生成)的原理,并说明它在医疗场景中的价值。
【参考答案要点】 ① RAG是一种结合外部知识检索与LLM生成的混合架构;② 核心流程:用户提问 → 向量化 → 检索相似文档 → 上下文拼接 → LLM生成;③ 医疗场景价值:解决LLM知识过时问题(医学知识动态更新),降低幻觉风险(用权威资料支撑回答),提升专业领域的回答准确性;④ 数据支撑:研究表明RAG可使医疗问答的临床准确性达0.89。
Q2:LLM Agent和RAG的区别是什么?它们如何协同工作?
【参考答案要点】 ① RAG是“知识获取”技术,解决LLM不知道的问题;Agent是“任务规划”架构,解决复杂多步骤任务;② 一句话概括:Agent是骨架,RAG是引擎;③ 协同方式:Agent在规划任务时,遇到需要专业医学知识的问题,会调用RAG模块检索相关文献;Agent还负责调用其他工具(如挂号API、药物数据库),RAG只是其中一种知识来源。④ 典型案例:MedRAG系统既用RAG检索知识图谱,又是完整的多模态Agent架构。
Q3:在设计医用AI助手时,如何平衡AI幻觉风险与效率提升?
【参考答案要点】 ① 引入RAG机制,让回答基于检索到的权威资料而非仅靠模型参数记忆;② 设置安全护栏(Safety Guardrail):通过Prompt约束回答范围,禁止生成诊断结论,强制要求“建议咨询医生”等免责声明;③ 引入知识图谱增强检索,构建因果关系链,减少推理错误;④ 引入人工复核机制:对关键回答(如用药建议)进行专家审核;⑤ 使用低温度系数(如temperature=0)降低输出随机性。
Q4:医疗场景中RAG相比通用RAG有哪些特殊挑战?
【参考答案要点】 ① 医疗知识专业性强且结构复杂:通用Embedding模型在医学术语上的语义表示可能不准确;② 数据隐私与合规要求:患者数据不能离开本地环境,限制了云端LLM的使用,需要本地部署或联邦学习方案;③ 推理深度与延迟的权衡:临床诊断需要多跳推理,但每一步检索都增加延迟,形成“医疗RAG三难困境”(推理深度、推理延迟、数据隐私三者不可兼得)-24;④ 答案可解释性要求高:医生和患者需要知道结论的依据,仅返回答案而不提供溯源信息是不可接受的。
Q5:开源医疗AI领域有哪些代表性项目?
【参考答案要点】 ① MedFound(176B参数,Nature Medicine 2025):当前最大开源医学语言模型,具备与临床专家媲美的诊断推理能力-50;② MedResearcher-R1(蚂蚁开源):医疗AI推理框架,包含知识图谱构建、轨迹生成和评估三大模块-51;③ MedRAG:多模态医疗助手,支持语音、文本、EHR多模态输入-54;④ Meissa(2026):多模态医学智能体,在医学图像理解与临床推理方面表现出色-。
八、结尾总结
回顾全文,我们系统地梳理了医用AI助手从技术痛点到底层原理的完整知识链路:
为何需要:传统医疗问答系统存在知识滞后、语义理解弱、扩展性差等根本性缺陷
核心概念:LLM Agent(让LLM“会做事”)和RAG(让LLM“会查资料”)
关系梳理:Agent是架构范式,RAG是实现技术,二者协同构成医用AI助手的完整技术栈
代码示例:基于LangChain+RAG的医用问答助手核心实现,标注了关键设计要点
底层原理:向量检索、Embedding、提示工程、多智能体协作、知识图谱增强RAG
面试要点:RAG原理与价值、Agent与RAG区别、幻觉应对策略、医疗RAG特殊挑战、开源项目梳理
重点易错点提醒:
❌ 不要混淆RAG和微调:RAG是检索外部知识,不改变模型参数;微调是在特定数据集上继续训练,改变模型参数。二者可互补,但解决的问题不同。
❌ 不要认为Agent就是RAG:RAG只是Agent可能调用的工具之一,Agent的核心是多步骤规划与执行。
❌ 不要忽略安全与合规:医疗场景下,任何输出都应有明确的来源标注和免责声明。
系列预告:下一篇将从底层原理深入,围绕医疗AI推理中的“三难困境” 展开,剖析为什么推理深度、响应延迟与数据隐私在医疗场景中难以兼得,以及当前学术界的前沿探索方向(如Agentic Workflows的延迟优化策略、本地化部署的隐私保护方案等),敬请期待。