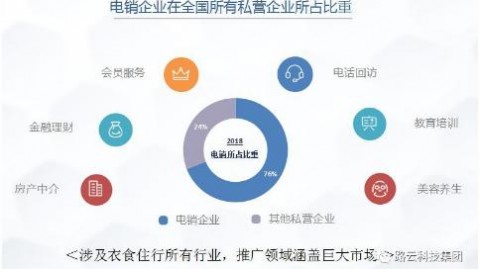
📊 开篇引入
如果说2025年是AI PPT工具的“元年”,那么2026年无疑是全面爆发的“应用之年”。据QYResearch最新数据显示,2025年全球智能PPT软件市场规模约为5.72亿美元,预计2032年将达到8.25亿美元,年复合增长率为5.4%-。另一份来自ResearchAndMarkets的报告则显示,2026年AI演示文稿生成市场规模已达24.3亿美元,预计2032年将增长至60亿美元-。从微软Copilot到Gamma AI,从Beautiful.ai到金山办公,几乎每个主流办公软件都在争相集成PPT AI助手功能。
面对这股技术浪潮,许多开发者和学习者却常常陷入“会用但不懂”的窘境——会用AI做PPT,却说不出背后的原理;见过各种工具,却分不清大模型生成与Agent协同的差异;面试中被问及PPT AI助手的架构设计,更是一筹莫展。本文将从市场背景出发,深入剖析PPT AI助手的核心技术与架构演进,通过代码示例展示开发实践,并整理高频面试题与标准答案,帮助读者建立从“会用”到“懂原理”的完整知识链路。
🔍 痛点切入:为什么传统PPT制作亟需AI助手?
在探讨PPT AI助手之前,不妨先审视一下传统PPT制作的痛点。以下是一个典型的传统制作流程:
传统PPT制作:纯手动流程 def create_ppt_traditional(topic): 步骤1:人工调研内容(耗时2-4小时) research_data = manual_search(topic) 步骤2:手动撰写大纲和文案(耗时1-2小时) outline = manual_outline(research_data) 步骤3:逐页排版设计(耗时2-3小时) for slide in outline: manual_design(slide) 调整字体、颜色、位置 manual_align(slide) 对齐元素 manual_format(slide) 格式统一 步骤4:添加图表和配图(耗时1-2小时) add_charts_manually() search_images_manually() return pptx 总耗时:6-11小时
传统制作方式的显著痛点:
耦合性高:内容与排版深度绑定,改一页文案可能需要重新调整整页布局
扩展性差:增加新章节或更换模板风格,往往需要从零开始重新排版
维护困难:数据更新后,图表和文字需要逐一手动同步修改
代码冗余:用VBA宏实现自动化时,代码量庞大且难以维护
门槛较高:专业排版需要设计知识储备,新手难以快速产出高质量PPT
正是在这样的背景下,PPT AI助手应运而生——它通过大模型的理解能力与生成能力,将内容创作、版式设计、数据可视化等环节自动化,让用户只需输入主题或上传文档,即可在分钟级获得结构完整、视觉专业的演示文稿-15。
⚙️ 核心技术概念(A):大语言模型(LLM)
标准定义:大语言模型(Large Language Model,LLM)是基于海量文本数据训练的深度学习模型,具备理解、生成和推理自然语言的能力。
核心内涵拆解:
“大” :参数量巨大,通常达到数十亿甚至万亿级别
“语言” :以自然语言为处理对象
“模型” :基于Transformer架构的神经网络
生活化类比:如果把制作PPT比作做菜,LLM就像一个经过米其林餐厅培训的厨师——它阅过海量菜谱(训练数据),知道“市场分析”这个主题应该包含哪些食材(内容模块),以及每道菜的摆盘方式(排版规范)。你只需要告诉它“做一份新能源汽车市场分析PPT”,它就能自行组织出一套完整的菜单。
核心价值:LLM解决了PPT制作中最耗时的“内容从0到1”问题。传统方式需要人工梳理思路、组织语言,而LLM可以在几秒内根据主题自动生成结构完整、逻辑清晰的大纲与文案,极大降低了内容创作的门槛。
🤖 核心技术概念(B):AI智能体(AI Agent)
标准定义:AI智能体(AI Agent)是一种能够感知环境、自主决策并执行动作的人工智能系统,通常具备调用外部工具(如、计算、渲染等)的能力。
它与LLM的关系:
| 维度 | LLM | AI Agent |
|---|---|---|
| 定位 | “大脑” | “大脑+手+眼” |
| 能力边界 | 生成文本/代码 | 调用工具、执行操作、视觉反馈 |
| 输出形式 | 文本输出 | 可执行的动作序列 |
| 典型局限 | 无法自主检索信息 | 可实时并验证信息 |
一句话概括关系:LLM是PPT AI助手的“思考中枢”,而Agent是让这个中枢“长出四肢”的架构模式——它让模型不仅能思考,还能动手做、亲眼看。
运行机制示例:用户输入“制作小米SU7介绍PPT”后,Agent工作流会依次触发:Research Agent自动检索相关数据 → Design Agent设计排版风格 → PPTAgent生成最终幻灯片-48。
🔗 概念关系与逻辑梳理
理解PPT AI助手的技术体系,关键在于厘清以下层级关系:
┌─────────────────────────────────────────┐ │ 用户需求(自然语言输入) │ └─────────────────┬───────────────────────┘ ▼ ┌─────────────────────────────────────────┐ │ Agent协同层(任务拆解与分工) │ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │ │内容Agent │ │视觉Agent │ │合规Agent │ │ │ └────┬─────┘ └────┬─────┘ └────┬─────┘ │ └───────┼────────────┼────────────┼───────┘ ▼ ▼ ▼ ┌─────────────────────────────────────────┐ │ 大模型引擎层(LLM + MoE) │ └─────────────────────────────────────────┘
核心逻辑:LLM是底层的生成能力,RAG是让LLM能访问实时数据的“信息管道”,Agent则是将LLM与工具结合、实现端到端任务执行的“架构框架”。三者共同构成了PPT AI助手的完整技术栈。
💻 代码示例:基于千帆SDK的PPT生成
以下是一个使用百度千帆SDK生成PPT的完整示例:
1. 安装依赖 pip install appbuilder-sdk --upgrade from appbuilder import PPTGenerator, Message 2. 初始化PPT生成组件 ppt = PPTGenerator() 3. 配置生成参数 config = { "template_id": "finance_report", 模板选择 "detail_level": "expert", 内容详细程度:basic/executive/expert "data_sources": ["web_search"] 数据来源配置 } 4. 执行生成任务 msg = Message(content="生成2026年Q1中国新能源汽车市场分析报告") result = ppt.run(message=msg, config=config) 5. 导出PPT文件 result.ppt.save("new_energy_vehicle_2026Q1.pptx") print("PPT生成完成!")
该SDK支持60+行业模板库的智能匹配,detail_level参数可根据需要调整输出精度-12。如需启用RAG实时数据检索,可额外配置:
启用RAG实时数据检索 ppt.set_rag_config( search_engine="baidu", freshness=24, 数据时效性:24小时内 domain_filter=["finance", "tech"] 领域过滤 )
执行流程解析:当调用ppt.run()时,系统经历了三个关键环节:①需求语义解析(提取主题、模块、风格要求)→ ②内容结构化编排(自动生成PPT大纲)→ ③多模态可视化生成(文字排版、图表生成、模板适配)-15。
🏗️ 底层原理与技术支撑
PPT AI助手的底层能力并非凭空而来,而是依赖于多个成熟技术栈的支撑:
1. 混合专家系统(MoE) :千帆组件基于文心大模型4.0,采用MoE架构,通过32个专家子网络的动态资源分配,针对PPT生成场景精准调用适配的专家网络,确保复杂内容的生成质量-11。
2. 检索增强生成(RAG) :为突破大模型训练数据的时效性限制,PPT AI助手集成RAG增强层,基于向量数据库构建检索模块,支持十亿级特征向量的毫秒级匹配-12。金融场景中财务数据图表生成误差率控制在0.7%以内-12。
3. 多智能体协同(Multi-Agent) :通过工作流引擎构建多Agent协同架构,将PPT生成拆解为内容生成(20页/15秒)、视觉优化(支持CI/CD集成)、合规审查(准确率99.1%)三大核心任务-12。
4. 开源生态支持:中科院软件所近期开源了第二代PPTAgent——DeepPresenter,这是业界首次将幻灯片智能体模型与完整智能体沙箱环境一同开源。它放弃了传统的“语言模型直接生成”路径,将智能体置入Docker沙箱环境,构建了“写→看→改”的视觉闭环,使模型能像人类设计师一样检查并调整排版效果-48。该模型仅以9B参数规模即实现了与GPT-5相当的性能表现-48。
📝 高频面试题与参考答案
Q1:请简要说明PPT AI助手的技术架构。
参考答案:PPT AI助手通常采用三层架构:(1)大模型引擎层,基于MoE架构的多模态大模型,负责文本、图表、版式的协同生成;(2)RAG增强层,集成向量检索实现实时数据融合,突破模型训练数据的时效性限制;(3)Agent协同层,通过多智能体分工完成内容生成、视觉优化、合规审查等任务。这三层通过标准化接口协同工作,实现了生成质量、数据时效性与开发灵活性的平衡。
Q2:RAG在PPT AI助手中起到了什么作用?
参考答案:RAG的核心作用是突破大模型训练数据的时效性限制。在PPT生成场景中,模型需要引用最新数据(如最新的市场份额、政策动态等),而模型训练数据可能存在滞后。RAG通过实时检索外部数据源(如引擎、企业内部数据库),将检索结果与模型生成能力融合,使PPT内容能够动态适配行业变化。具体实现上,系统将用户查询转化为向量,在向量数据库中进行相似度匹配(支持十亿级特征的毫秒级匹配),召回相关内容后与大模型结合生成最终输出。
Q3:传统LLM生成PPT存在哪些问题?AI Agent如何解决?
参考答案:传统LLM生成PPT存在两大核心挑战:一是内容层面,LLM缺乏主动检索能力,容易产生事实性错误或内容空洞;二是排版层面,LLM无法感知最终渲染效果,常出现排版错乱、元素遮挡等视觉缺陷。AI Agent通过“工具调用”和“环境感知”解决这些问题:Agent可调用工具实时检索权威文献,并通过Docker沙箱渲染出真实排版效果,“亲眼”检查后进行自适应调整,形成“写→看→改”的视觉闭环,确保内容的专业度与排版的准确性。
Q4:如何评估一个PPT AI助手系统的性能?
参考答案:评估可从三个维度展开:(1)内容维度——检查生成内容的准确性、相关性与逻辑连贯性;(2)设计维度——评估视觉吸引力与风格一致性;(3)效率维度——包括生成速度(如20页/15秒)、并发支持能力(如单节点200并发请求)、响应时间(如低于800ms)。还可关注段落分割准确率(如94.3%)、图文一致性(如92.7%)等技术指标。
Q5:PPT AI助手的市场前景如何?
参考答案:据QYResearch数据,2025年全球智能PPT软件市场规模约5.72亿美元,预计2032年将达8.25亿美元,年复合增长率5.4%。同时,2024年中国智能办公软件市场规模已突破300亿元,其中演示文稿类工具渗透率达43%。主要增长驱动因素包括:企业数字化转型加速、远程办公常态化、以及AI技术在教育、金融、营销等垂直场景的深入应用。
✅ 结尾总结
回顾全文,我们完成了以下知识点的系统梳理:
| 知识点 | 核心内容 |
|---|---|
| 市场规模 | 2025年约5.72亿美元,2032年预计达8.25亿美元 |
| 核心痛点 | 传统PPT制作耦合性高、扩展性差、耗时冗长 |
| 核心技术 | LLM(思考中枢)+ RAG(实时检索)+ Agent(执行架构) |
| 三层架构 | 大模型引擎层 → RAG增强层 → Agent协同层 |
| 关键指标 | 图文一致性92.7%、段落分割准确率94.3%、合规审查准确率99.1% |
| 面试要点 | 架构分层、RAG原理、Agent与LLM关系、性能评估维度 |
重点与易错点提示:
⚠️ 区分LLM与Agent:LLM是生成能力本身,Agent是调用工具和感知环境的执行框架
⚠️ RAG≠联网:RAG是包含检索、向量化、融合生成在内的完整流程,不是简单的API调用
⚠️ MoE不是越多专家越好:32个专家子网络是通过动态门控机制选择性激活,而非全部使用
本文从市场背景、技术原理、代码实现到面试考点,建立了PPT AI助手的完整知识链路。后续可以深入探讨各架构层的具体实现细节,如MoE的负载均衡策略、Agent的提示工程优化、以及如何基于LangChain从零搭建PPT生成系统。欢迎持续关注本系列后续内容!
本文基于QYResearch、ResearchAndMarkets等机构2026年最新市场数据,以及百度千帆、中科院DeepPresenter等公开技术资料整理撰写,力求数据准确、内容客观。